Достойная альтернатива Ceph

При развертывании приложений в облачной среде на основе OpenStack, пользователи нередко выдвигают требования к блочному хранению, которые трудно, а иногда и невозможно совместить в одной системе хранения.
Наиболее популярной система хранения с открытым исходным кодом для использования в составе проекта на основе OpenStack является Ceph. Но помимо таких достоинств, как надежность хранения данных, масштабирование емкости хранилища, эта система хранения не лишена и ряда недостатков. Главный среди них – это латентность (задержка), время, которое требуется на выполнение операции ввода-вывода. Безусловно, использование быстрых дисков и высокой полосы пропускания на уровне сети позволяет несколько улучшить ситуацию, но по показателю латентности Ceph все равно серьезно уступает классическим системам блочного хранения. И это при том, что в составе OpenStack, классические блочные системы хранения, объединенные в единый пул хранения, способны обеспечить неограниченное масштабирование как по емкости хранения, так и по суммарной производительности. Но как же дело обстоит с надежностью хранения и доступностью данных в случае отказа одного из узлов хранения? Этот вопрос нередко встает на повестке, когда начинают сравнивать кластерную систему хранения, аналогичную Ceph и традиционную блочную СХД. Как показывает наш опыт, немногие администраторы OpenStack знают, что Cinder API уже предоставляет инструмент восстановление доступа к данным после сбоя. Это API включает:
- Создание отказоустойчивого ресурса/сервиса хранения с поддержкой репликации данных. Тут стоит сразу сказать, что количество хранимых реплик может быть любое, а протоколы репликации могут варьироваться от синхронного до асинхронного, в зависимости от удаленности хранения реплик и принятой политики восстановления после сбоя.
- Переключение томов блочных устройств на один из резервных узлов хранения, в случае выхода из строя или недоступности основного узла хранения.
- «Заморозка» (freeze)- блокировка операций управления жизненным циклом блочного устройства (расширение блочного устройства, его удаления, снятие снимка) с сохранением операций ввода / вывода данных.
- Возврат к исходному состоянию, обеспечивающий выполнение операций на основном сервере, как только он станет доступным/работоспособным.
- «Разморозка» (thaw) – полная разблокировка операций управления жизненным циклом блочного устройства.
Используемый администратором драйвер должен поддерживать репликацию, а создаваемый администратором тип блочного устройства должен быть сконфигурирован в соответствии с требованием документации OpenStack Cinder.
С точки же зрения самого пользователя — работа механизма репликации скрыта, а сам процесс восстановления после сбоя мало чем отличается от алгоритма, реализованного сервисе AWS EBS облака Amazon. Все что нужно для возобновления доступа к своим данным в случае отказа основного узла хранения – это переключиться на том восстановления. Для пользователя – это выглядит как переподключение виртуального блочного устройства (диска).
Взамен же, пользователь получает сервис хранения, который, особенно в связке с применением выделенных (dedicated) ресурсов, может быть использован под высоконагруженные, критические рабочие нагрузки, таких как базы данных ERP и CRM систем. Драйвера, реализующие репликацию, могут поддерживать различные режимы синхронизации данных, такие как синхронный или асинхронный, что позволяет строить и метро кластера хранения данных, опираясь на тот или иной режим, в зависимости от расстояния между первичным и резервным бэкендом. Переключение на том восстановления в момент аварии – это, пожалуй, единственная плата за такие возможности. И надо всегда помнить, что описываемый здесь сценарий представляет собой восстановление после сбоя (Disaster Recovery).
Для того, чтобы получить возможность работы с отказоустойчивым бэкендом, необходим драйвер, который поддерживает репликацию и соответствующий API OpenStack Cinder. Итак, перейдем к практическим действиям, воспользовавшись возможностями, которые предоставляет Cinder драйвер программно-определяемого слоя хранения гиперконвергентной инфраструктуры ОТВ эв3.
Первое, что нужно выполнить администратору – это создать тип блочных устройств, маркированный как реплицируемый, как показано на примере ниже, на снимке с экрана:

В вызове нет ничего особенного, кроме одного дополнительного свойства
— replication_enabled='<is> True‘ Именно оно обеспечивает всю дальнейшую логику работы бэкендов хранения, относящихся к подобному типу блочных устройств в режиме отказоустойчивости. Давайте рассмотрим работу отказоустойчивого бэкенда на живом примере.
Спецификация OpenStack Cinder требует поддержки драйвером свойства replication_device. Здесь, в обязательном порядке, должен быть указан backend_id – резервный бэкенд, на который будет идти репликация данных с настраиваемого узла.
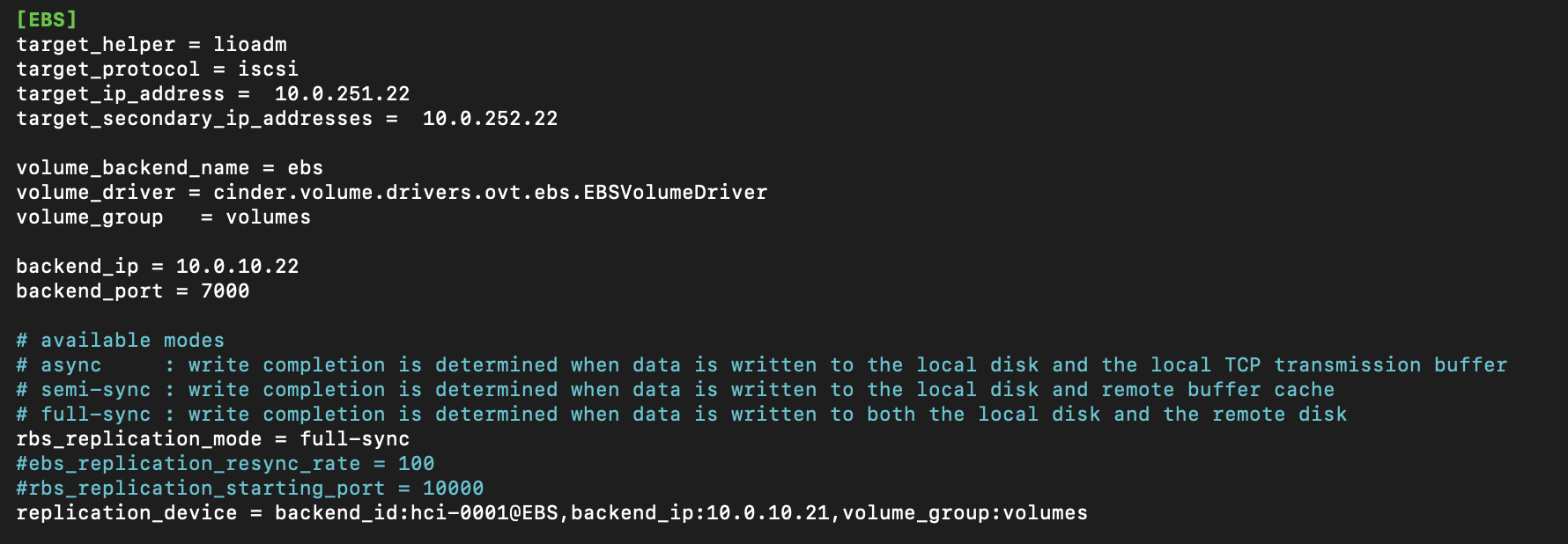
Этот резервный бэкенд предоставит тома восстановления, в случае сбоя основного и обеспечит доступ пользователя к своим данным.
После регистрации драйвера, администратор может получить представление о том – на какое устройство будут реплицированы данные, для этого нужно вызвать команду:
openstack volume backend pool list –long
Стоит обратить внимание, что в показываемом примере, данные только одного узла, а именно hci-0002 будут реплицироваться в то время, как hci-0001 на репликацию данных не настроен и выступает исключительно в качестве резервного бэкенда.

Это – один из возможных сценариев. Таким образом, в этом примере, hci-0001 — выступать резервным бэкендом, в hci-0002 первичным бэкендом хранения, с которым в норме взаимодействует пользователь. Все, что нужно сделать администратору для окончания настройки, это вызвать команду:
cinder failover-host hci-0001@EBS —backend_id hci-0002@EBS
В результате, хост hci-0001 будет помечен (failed-over) службой OpenStack Cinder в качестве резервного бэкенда по отношению к hci-0002.
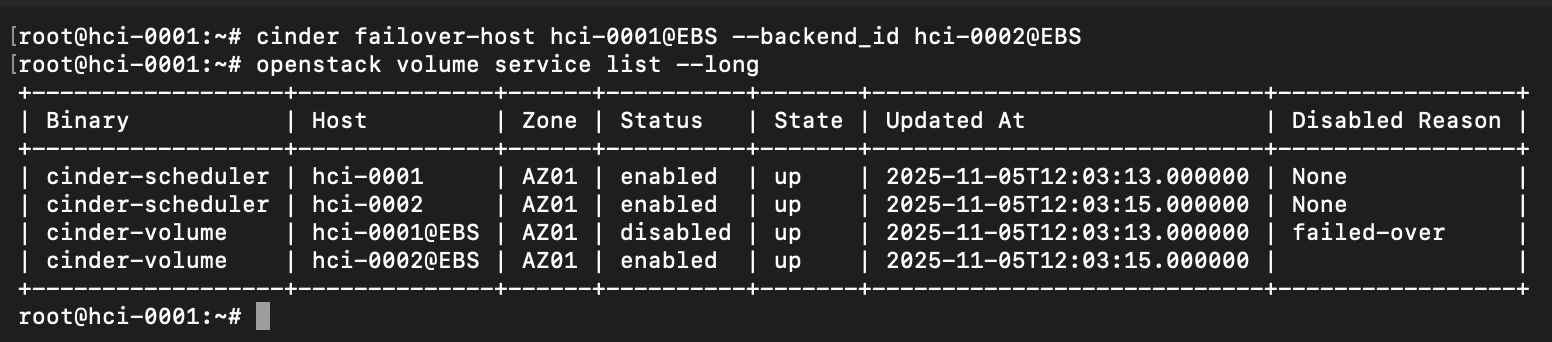
Если пользователи уже успели создать блочные устройства hci-0001, драйвер обработает эту ситуацию и автоматически переназначит хост владельца, указав текущий primary backend.
Стоит обратить внимание, что как только выполнена маркировка узла хранения в качестве резервного, он становится недоступным и для планировщика.

Теперь, блочные устройства, которые будет создавать пользователь, будут помечены как реплицируемые, обратите внимание на поле replication_status и os-vol-host-attr:host на снимке экрана ниже:
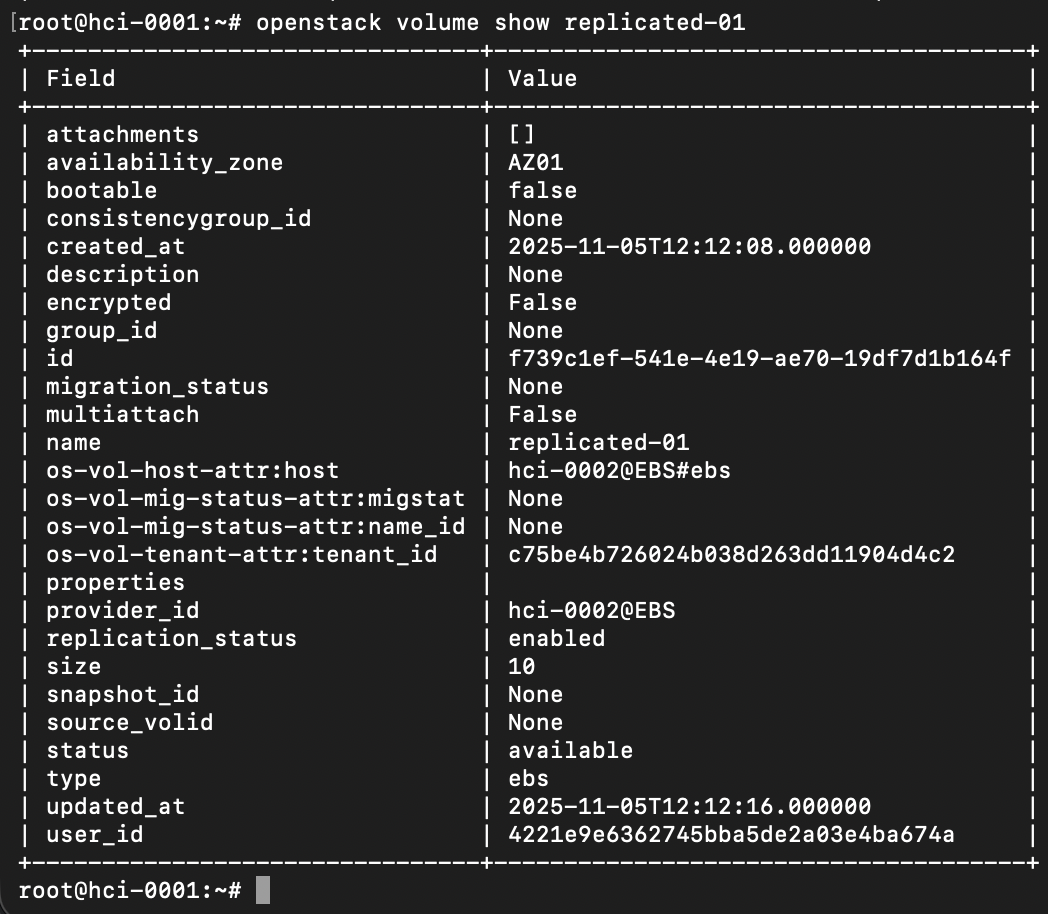
Если все настроено корректно, то мы увидим, что том имеет значение replication_status enabled.
Подключим реплицируемое блочное устройство к ранее созданному серверу
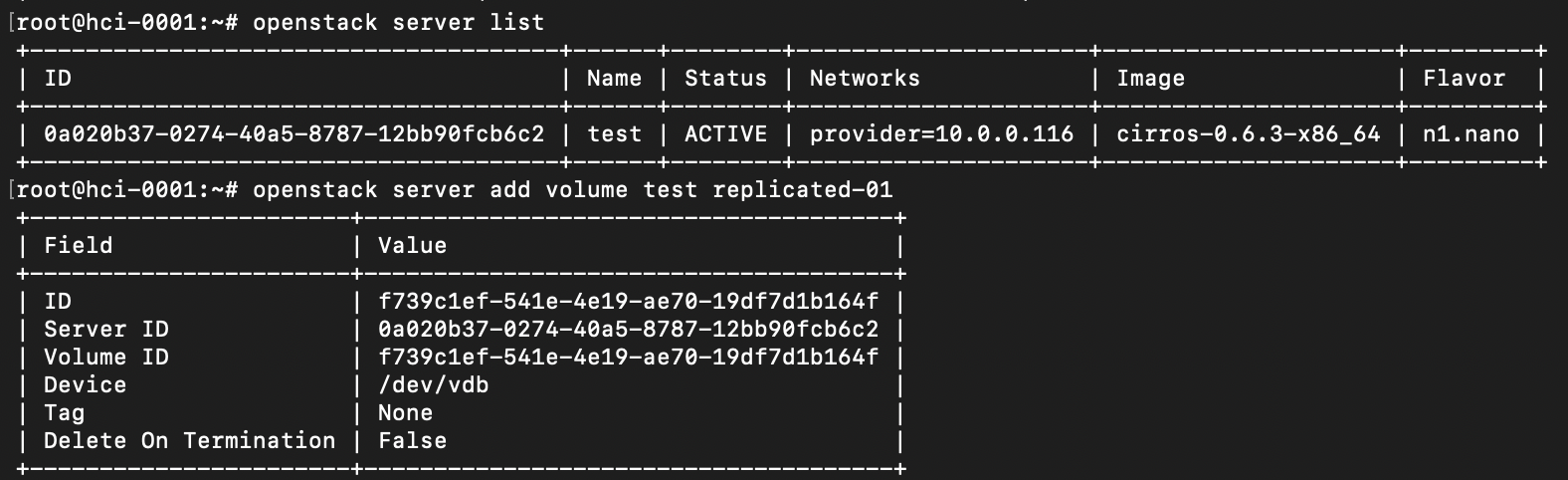
Как можно видеть, блочное устройство получило информацию по подключению
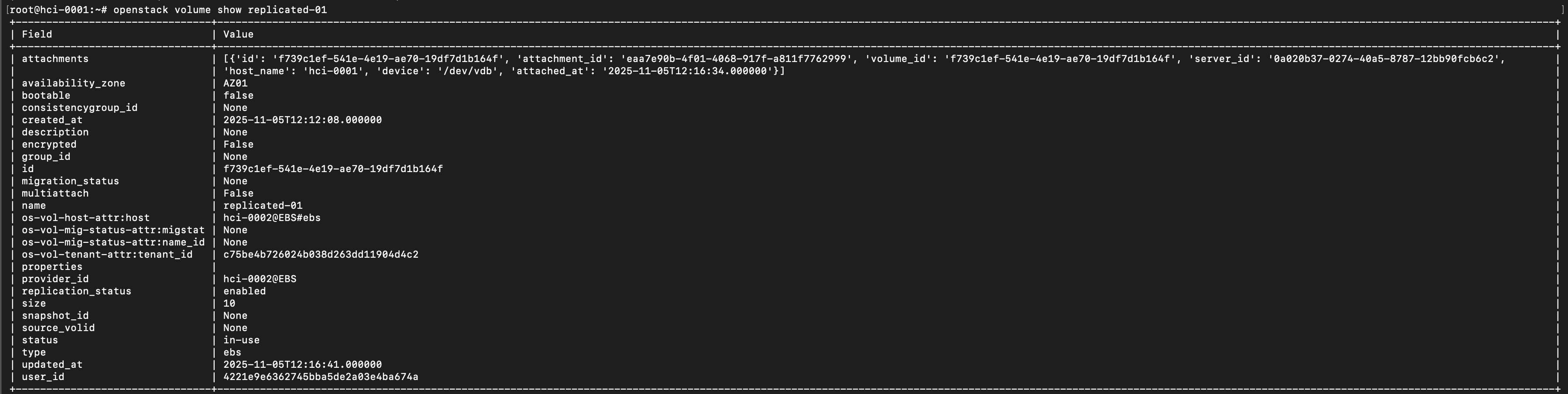
Войдя непосредственно на сервер, можно убедиться, что блочное устройство доступно.
Теперь перейдем продемонстрируем работу механизма отказоустойчивости доступа к данным, выключим узел hci-0002, являющийся первичным бэкендом хранения блочных устройств.

Просмотр состояние сервисов OpenStack Cinder показывает, что все сервисы на хосте hci-0002 теперь недоступны.
Для того, чтобы восстановить доступ к данным, администратору необходимо выполнить всего две команды: поменять значения os-vol-host-attr:host для всех блочных устройств отказавшего узла, указав в качестве нового значения резервный бэкенд:
cinder-manage volume update_host —currenthost hci-0002@EBS#ebs —newhost hci-0001@EBS#ebs
и перевести резервный бэкенд в рабочее состояние, командой
cinder failover-host hci-0001@EBS —backend_id default

Пользователю же, достаточно выполнить всего две команды
openstack server remove volume test replicated-01
openstack server add volume test replicated-01
то есть выполнить переподключение блочного устройства и убедиться, что данные его доступны, как и прежде.
Как можно видеть, блочное устройство теперь доступно с резервного узла hci-0001
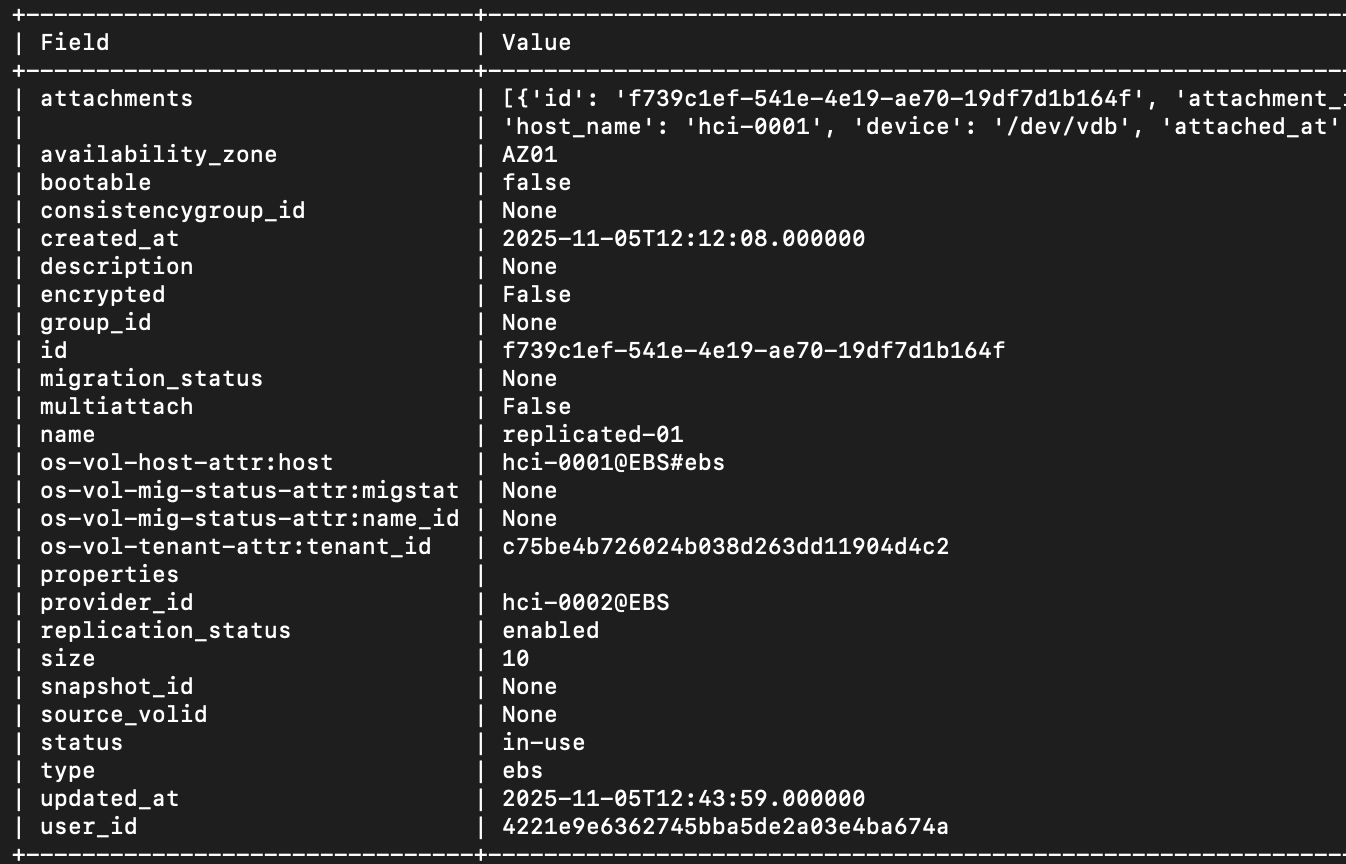
Стоит добавить о временной «заморозке» изменений блочных устройств, до тех пор, пока сохраняется проблема доступности первичного или вторичного (резервного узла). Эта операция рекомендуется документацией OpenStack Cinder выполняется, применительно к рассматриваемой конфигурации командой
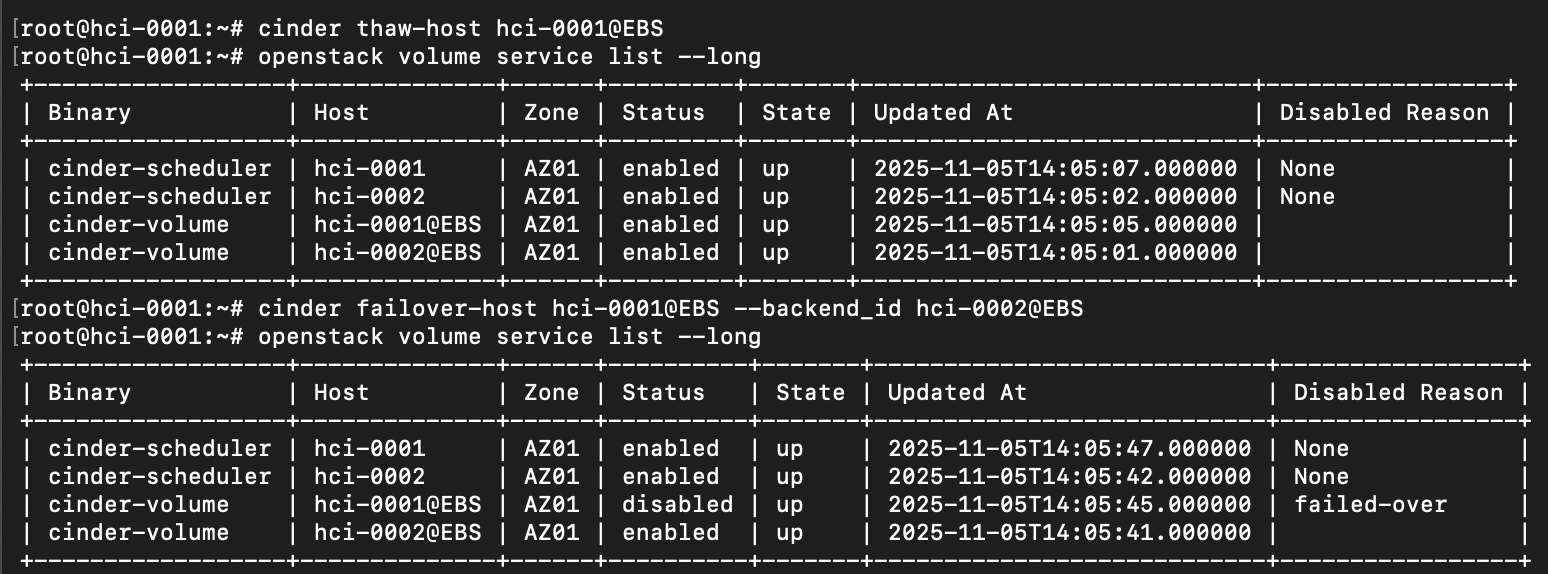
cinder freeze-host hci-0001@EBS
В результате, как видно из снимка с экрана, резервный узел будет переведен в статус disable, а служба Cinder Volume пометит хост как frozen

Как только, проблема будет устранена и узел hci-0002 будет возвращен в эксплуатацию, администратору необходимо будет вызвать набор команд, которые вернут оба бэкенда к своему исходному состоянию:
cinder thaw-host hci-0001@EBS
cinder failover-host hci-0001@EBS —backend_id hci-0002@EBS
Исходный код драйвера Cinder размещен здесь: https://github.com/ovtsolutions/ev3
И это – все…
И напоследок, хотелось бы обратить внимание читателя на то, что драйвера к проприетарным (хоть к блочным, хоть к NFS) системам хранения данных, в большинстве случаев реализуют и поддерживают именно такой, описанный выше сценарий репликации и восстановления доступа к данным.
P.S. Отдельно, хочется отметить, что в качестве одного из «подопытных» в демонстрационном сценарии репликации хранимых данных выступал узел на РЕД ОС 8.0 (hci-0002).